 jω
jω processor - HELP
processor - HELP
An interactive SaxonJS/JavaScript workbench processor of Invisible XML - Workbench Version 1.4
processor - HELPAn interactive SaxonJS/JavaScript workbench processor of Invisible XML - Workbench Version 1.4
TODO:
For the runtime files for the iXML processor and a sample jωiXML application see here.
This workbench runs entirely within the browser client, using SaxonJS as the top-level program and the jwiXML JavaScript library. There is no server-side processing, apart from initial delivery of necessary files.
You can input and edit an iXML grammar either ab initio or by loading from a file on your computer or one of the test-case or sample grammars from the iXML GitHub repository. The input string can also be edited or loaded from file or, in the case of a test-case or sample grammar, by selecting from one of a number of provided input strings, relevant to the grammar in question.
Local file selection is either by a conventional selector dialog or by drag-and-drop of a file onto the relevant text area. (Note that on Firefox security hurdles may preclude drag-and-drop.)
iXML grammars are edited in the upper textarea, where usual keystokes are supported, but there is no 'syntax awareness' during input:
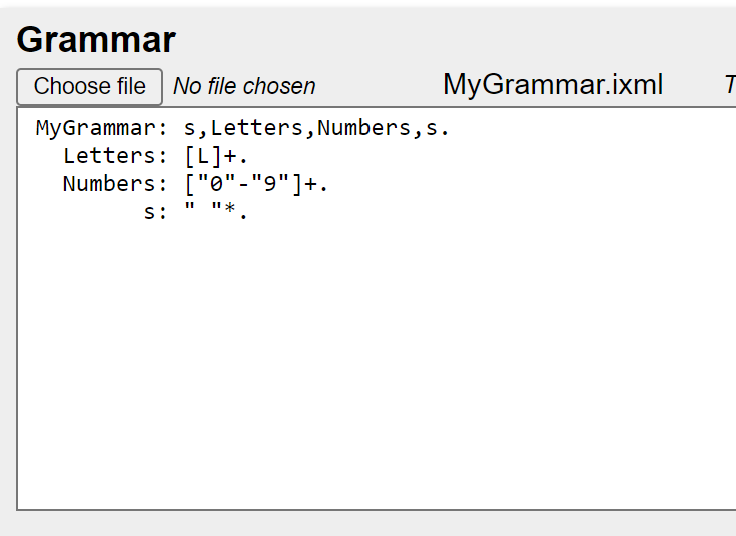
The 'format' button above the textarea will, for a valid grammar, 'pretty-print' by
replacing the text with a canonical ixml rendering of the parsed grammar.
This form will line up all the rules so all their names are right aligned and their
definitions left-aligned. Strings should be enclosed in the quotation characters used
in the original (doubling such characters within the string as necessary). For
alternatives, the separator character used is the first separator character (i.e.
';' or '|') encountered whilst parsing that set of
alternatives. If the serialisation of the definition of a rule will be longer than 50
characters, top-level alternatives will have a newline and appropriate indentation
attached to their separators.
This means that, for instance, an original line of the form:
a: [L] | "s" ; '"', #a; bcdef ; bcdef ,"a", bcdef; bcdef, "b", bcdef.
bcdef: [N]|("1"; "2" | "3").
will be formatted to
a: [L]|
"s"|
'"',#a|
bcdef|
bcdef,"a",bcdef|
bcdef,"b",bcdef.
bcdef: [N]| ("1";"2";"3").
Input strings to be parsed by that grammar are edited in the lower text-area:
The size of both of the textareas can be adjusted (at least on Chrome and Firefox) by the resizer 'chevron' at the lower right hand corner.
With the grammar and potential input string edited, clicking on the GO! button causes the following actions:
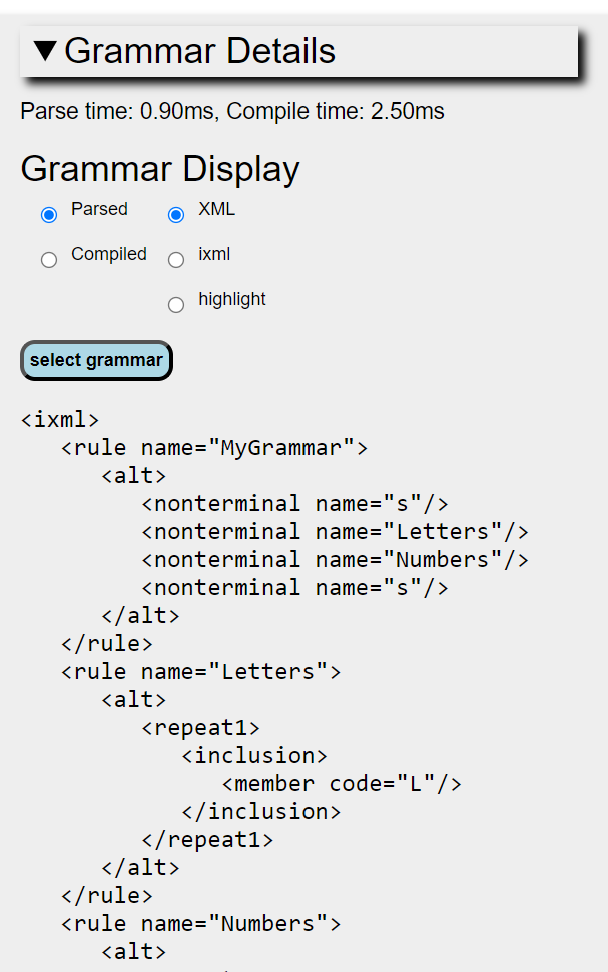
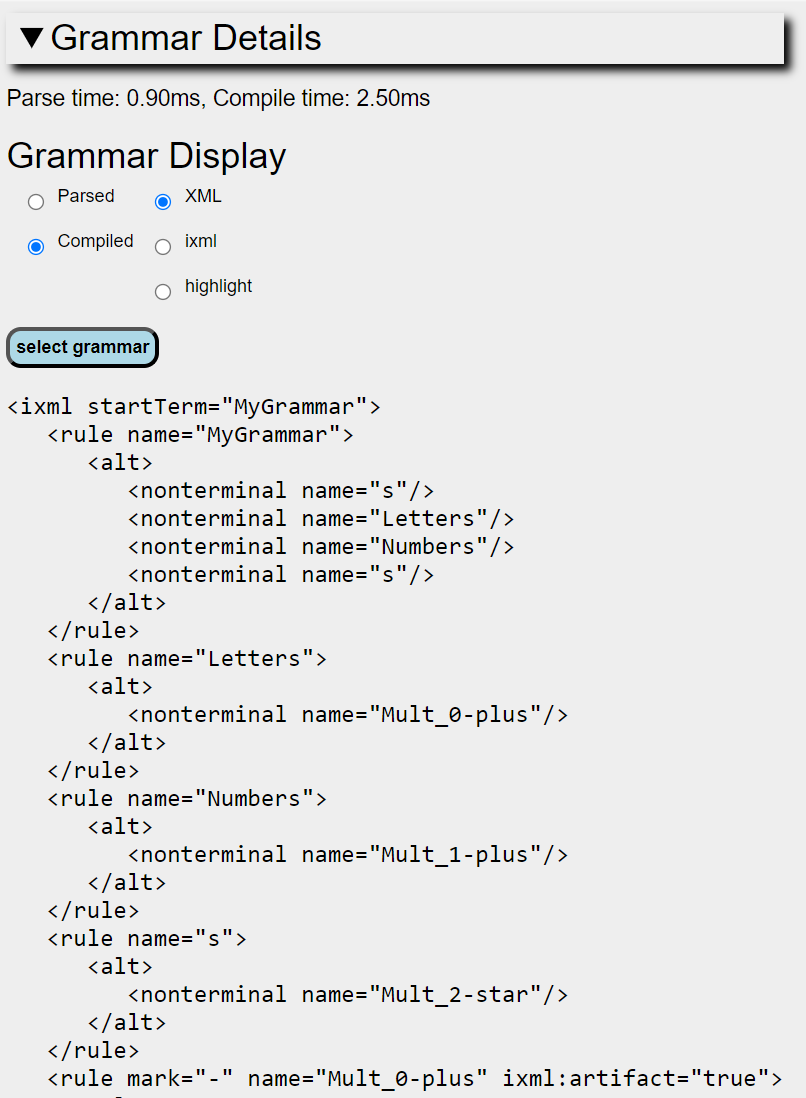
The grammar defined by the text in the Grammar window is parsed and compiled as an iXML grammar to produce an internal object representing the compiled grammar. Assuming the grammar has valid iXML syntax, this is then displayed in the 'Grammar Details' section (which is normally hidden - just click on the bar to reveal or hide).
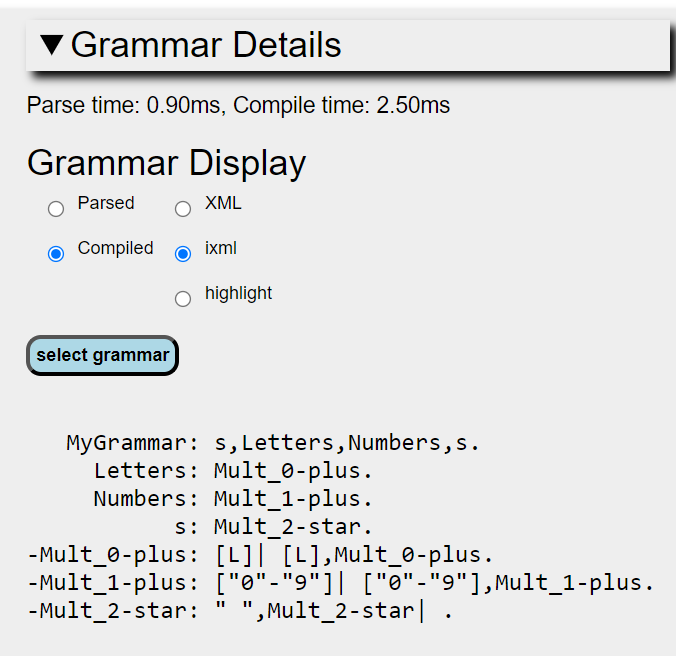
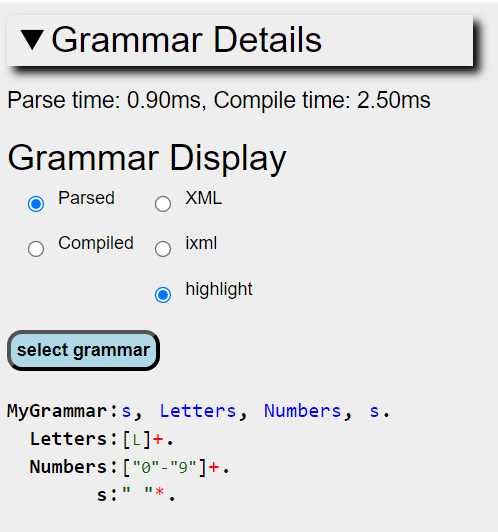
Here various projections of the grammar can be displayed either in XML format or an iXML textual serialisation, or a colour-highlighted iXML form. Either the original parsed grammar or the compilation (i.e. where the grammar has been reduced to a canonical form) thereof can be shown.:
|
|
|
|
If you want to copy the parsed XML-format grammar the 'select grammar' button will select the whole of the grammar XML, so a simple 'Copy' keystroke action can get it into the clipboard as text.

Assuming the grammar has compiled and the input text string is not empty (or the 'Allow an empty string as input' option is checked), the text string is then parsed against the grammar, giving results in the Results section.
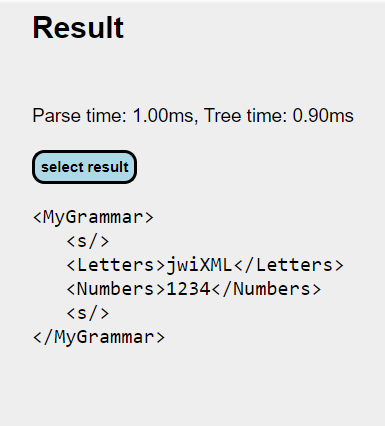
As with the parsed grammar, if you want to copy the resulting XML, the 'select result' button will select the whole of the result XML (and multiples if ambiguous or record-oriented processing was performed), so a simple 'Copy' keystroke action can get it into the clipboard as text.
There are three main categories of errors detected:
Errors in the iXML grammar presented will be displayed under the 'Grammar Details' section. Such errors can be one of:
Grammar failure G000: Invalid rule syntax. Missing rule terminator character. Expecting character:'.' - given: 'p' (codepoint 112). Near line 9, column 2. product: term, "×", operand. ^and
Grammar failure S10:
A Unicode character category code must match [A-Z][a-z]?. Provided: 'LZ'.
Near line 11, column 8.
id: [LZ].
^
The grammar supplied, whilst grammatically correct (i.e. its text parses correctly) is invalid. Such cases include
| Condition | Example |
|---|---|
| There are references to non-terminals for which a rule definition has not been provided. |
Grammar failure S02: No production rules for non-terminals: number |
| There are multiple rule definitions for a non-terrminal. |
Grammar failure S03: Adding productions for an already-defined non-terminal: id |
| There are non-terminal rule definitions which are unreachable through reference from the starting rule. This will only be detected if the Prohibit unreachable non-terminals option has been checked. |
Grammar failure S002: Unreachable production rules for non-terminals: b |
The parsing of an input string against a valid iXML grammar can fail for a number of
reasons. Such errors are displayed in the 'Result' portion of the workbench,
currently as, in line with the specification, an XML document with
@ixml:state="failed" on the topmost element, such as:
<ixml xmlns:ixml="http://invisiblexml.org/NS" ixml:state="failed">
Failure at line 1 column 2
Given '/' (codepoint 47). Expecting one of:
"+" {#8: sum: term, "+", term++"+".},
"×" {#10: product: term, "×", operand.},
[<=>≠≤≥] {#4: compare: ["<=>≠≤≥"].}
Input:
a/b
^
</ixml>
where an unexpected (operator) character was encountered. In this case the processor attempts to identify what characters would have been admissable at this point in the parse, and in which rules (identified by line number and with original source) the parse failed. (This is currently not available for internally-generated rules, such as those for repetition constructs.)
In cases of high potential ambiguity, such as the grammar:
specification: "{", rule*, "}".
rule: definition*.
definition: id, "=", value.
id:[L].
value:[N].
when run with an input that can trigger such ambiguity, such as {}
(possible solutions could include no rule or a potentially infinite sequence of rules
each containing no definitions) the jωiXML processor can get into an
infinite loop. Internally there is a limit of triggering 1000 productions on
processing a character from the input string. If this limit is reached a failure will
assumed:
<ixml xmlns:ixml="http://invisiblexml.org/NS" ixml:state="failed">
Probable looping processing character '{' @ line 1, column 1</ixml>
The input string may have parsed correctly, but it is still possible that the conversion (serialisation) to XML fails as the resulting tree would not be a valid XML document. In such cases the error is reported, again in the 'Result' section:
<ixml xmlns:ixml="http://invisiblexml.org/NS" ixml:state="failed"> An attribute node may not be the final parse result @input</ixml>
or
<ixml xmlns:ixml="http://invisiblexml.org/NS" ixml:state="failed"> Multiple nodes may not be the final parse result:<expression/>,@compare,<expression/></ixml>
Note that when 'Treat as records' is enabled, multiple document trees can be generated and will be serialised in sequence in the result display.
The following actions on grammars displayed in the grammar textbox are supported via simple buttons:
| Action | Effect |
|---|---|
| reformat | Pretty-print the ixml grammar to a standard format, where all rule names are right-aligned, and non-simple (non-terminal and multiple terminals) top-level alternatives are placed on newlines |
| reduce | Transform the given grammar into a 'reduced tree' version (which will have most single-child parent elements removed). See the section "Truncation of Deep Trees" of “Variations on an Invisible Theme" for more details |
The following options controlling grammar parsing, input string treatment and result display are supported via checkboxes. Where appropriate the corresponding option or invocation in the jwiXML.processor API is described:
| Option | Default | Effect | API equivalent |
|---|---|---|---|
| Show Advanced options | Make the advanced (and experimental) options visible. Ordinarily these shouldn't be needed - the defaults maximise the comformity of the processor. See the table below for a description of these options. | ||
| Prohibit unreachable non-terminals | When checked, all non-terminals in the grammar must be reachable through a reference path from the start (first) rule. | compile() option 'unreachable' | |
| Allow an empty string as input | Normally if the input is an empty string, no attempt is made to parse - just the grammar is processed and displayed. Checking this allows processing of an empty string as input, which is probably only needed for certain test cases. | ||
| Treat as records | When checked, the input is assumed
to be a sequence of records separated by character sequences which match a given
regular expression (for which '\n' is the default). The separator can be
edited in the displayed text input, when this option is selected. The result is a sequence of documents, each serialised in the output result area as children of the 'parent' element, which can be edited For repetitively structured data where the repetition separators do not appear in the data 'records' this technique can be vastly more efficient than describing the repetition/separation in the iXML grammar itself. |
parseRecords() 3rd argument $separator | |
| Show only one ambiguous solution | When the parse is ambiguous, with multiple possible solutions, this forces only one to be returned, which will still be marked as ambiguous. | parse() option 'justOne' | |
| Indent result | When checked, the results will be displayed as a serialization of the XML tree with indentation applied. This means that whitespace-only text nodes may be altered or in some cases deleted. If your application requires strict whitespace preservation, uncheck this option. | ||
| Indent with a single space per level | When checked, the results, if indented, will be displayed with a single additional space of indentation per tree-level depth (as opposed to the default 3.) This is intended to make very deep trees display 'narrower' in the serialisation (and avoid really wide scrolling displays). |
| Advanced Option | Default | Effect | API equivalent |
|---|---|---|---|
| Permit missing non-terminals | When checked, missing non-terminals may be referenced in the grammar (e.g. for experimentation in grammar combination). Using this during input parsing will lead to unpredictable results - usually some sort of crash. | compile() option 'missing' | |
| Tovey-Walsh rewrites | When checked, f+ constructs are
rewritten as f+ => f-plus. f-plus: f, f-plus| (). rather than the
f-plus: f, f*. rewrite given in the spec. This is currently the
default, as it seems to perform significantly quicker. |
compile() option 'twRewrites' | |
| Show Parser States | Displays the internal state transitions of the Earley parser operating on the input. This is NOT recommended for use with large grammars and inputs as memory overflows can be encountered. | ||
| Show all processed marks | If checked, directive marks for deletion
('-'), attribute ('@') or rename aliasing ('>') serialisation of
non-terminals, or deletion ('-') or insertion ('+')
serialisation of quoted strings are not honoured but rather
placed on the full parse tree output either as an @ixml:mark or
@ixml:alias attribute or an ixml:insert or
ixml:delete element. This ony applies to marks on the original grammar and not to artefactual marks generated in compiling the grammar, such as those used for generated non-terminals implementing optionality or repetition. |
parse() option 'suppressMarks'' | |
| Support iXML version 1.1 | Support additional features of iXML version 1.1 (e.g. renaming) | ||
| Keep multi-character strings | Multi-character terminal strings
(corresponding to the quoted production of the iXML spec.) are
expanded during compilation to a sequence of single (quoted)
character strings, to correspond to a character-by-character processing of the
Earley parser. If this option is checked such strings are retained as multiple
characters and the Earley parser 'jumps-forward' to write a new state several
character positions forward in its state records. |
compile() option 'longStrings' | |
| Use regular expression matches | Uses regular expression matching for quoted strings, inclusions and exclusions and in some cases repetition and optional forms of the same. This will only work properly when the ranges of characters matched by the following term in sequence can be guaranteed disjoint with that of the current term. Automatic determination of safe conditions to do this is a type-analysis research issue. | compile() option 'regEx' | |
| Max state loops | 1000 | Set the limit on the number of state-generating processing loops per input character during the parse. If this limit is exceeded, the parse will terminate. | parse() option 'loopLimit' |
| Parse timeout/ms: | 4000 | Set the time limit (in milliseconds) for the complete parse. At the completion of each character of input this timeout is checked - if exceeded, the parse will terminate. Due to the single-thread nature of JavaScript, this is the only way, without significant overhaul of the entire parser architecture, to limit runaway parsing in cases of very high ambiguity. | parse() option 'parseTimeout' |
Both grammar and input texts can be read from local filestore by using the appropriate 'Choose file' (or 'Browse') button, which permits a file to be read and its text loaded into the textarea. The name of the file loaded is displayed next to the file chooser. Files can also be 'drag-and-dropped' onto the textarea, though in Firefox security settings will probably have to be altered (it seems to work fine in Chrome).
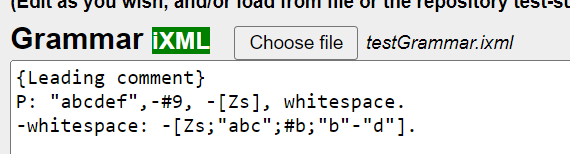
Grammars can also be loaded from web-repositories, in particular from the InvisibleXML test-suites or sample grammars using the Grammar 'Test/sample' dropdown:
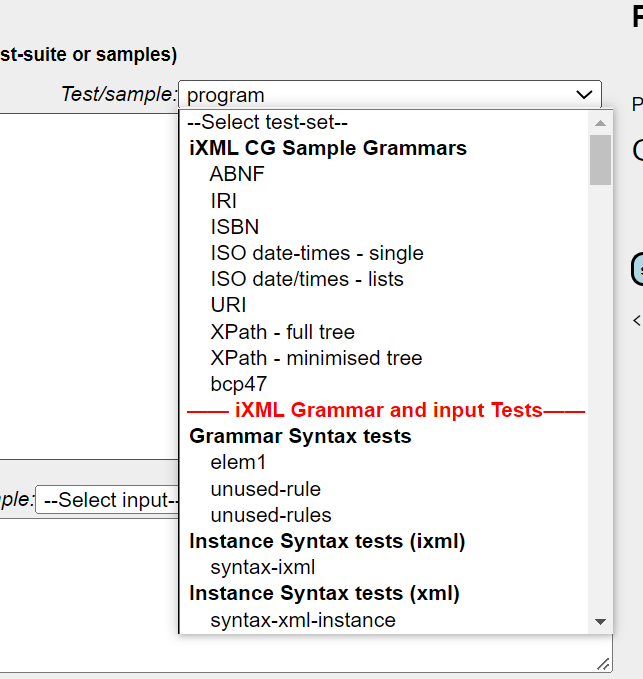
A browsable catalog of the test suite is also available.
When there are sample inputs available for one of these test or sample grammars, the 'Test/Sample' dropdown above the Input textarea will be populated.
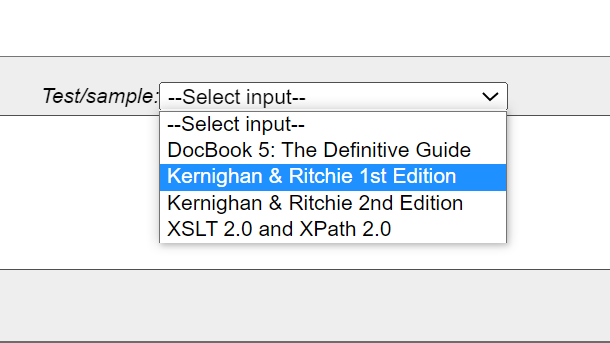
Note that some of these test cases provide the iXML grammar in its XML serialisation
form. The workbench recognises such a situation and will show and use that form, but
editing in the textarea under these circumstances will have no effect on the
grammar being used in parsing. Files containing iXML grammars serialised as
XML loaded by other means (file selection, drag-and-drop) will be (currently) treated
as simple text and currently will therefore fail to be parsed. (The jwlProcessor.xsl library contains
a jwl:parseXML() function that will accept
XML-serialised grammars)
I've been involved in the QT4 Community Group since its start, and have been using the grammars for XPath and XQuery as large test examples for this iXML processor. These grammars are also available to support experimentation for those involved in that community to perhaps handle 'what-if' experiments on the grammar.
The 'Test/Sample' dropdown contains (at the top) iXML grammars for the 'near-current' draft 4.0 versions of the Xpath and XQuery grammars. These are derived programmatically (with a modicum of automated patching) directly from the grammar definitions used to generate the specification grammars XPath EBNF and XQuery EBNF. (See my Balisage paper for details of how these are constructed.)
The grammars are presented in three different versions of iXML:
1.0, the published standard,1.1, the current draft which noteably adds the ability to rename
nonterminals (A>b). This is used in areas such as QNames to
accomodate both prefix and local parts as attributes, and1.1+, being the 1.1 version with the addition of a
set-subtraction operator (see below), which is used to exclude certain reserved
keywords from nome name concepts, such as function being reserved from
use a the name of a function call. As far as I'm aware, this iXML feature is not
currently supported by any other implementation and whilst having been
proposed as an additional part of iXML, decisions on it have not yet been made.For both these grammars, there is also a 'reduced tree' version which truncates the very deep trees that normally result from parsing. A suitable moderately large sample expression to test parsing is included for each grammar.
Each of the (iXML) grammars contains a date-stamp in a comment near the top which can be used to verify whether it is 'up to date', by comparison with the history of the file: https://github.com/qt4cg/qtspecs/blob/master/specifications/grammar-40/xpath-grammar.xml
Whilst the grammars have been tested across the 35k expressions of the QT4 test sets, with only some 50 failures, there are known areas where the grammar fails or produces ambiguity. These notes are intended to explain.
-) unsurrounded by whitespace, e.g. 1-1, but others can
include examples such as if(foo)else, etc. Attempting to cure these
will give rise to explosive ambiguity, especially in supporting a binary minus
without surrounding whitespace. In the 35k tests, these failures occur about 20
times. The grammars, lacking a tokenizer and the ability to look-ahead without consumption, retain a few ambiguities that are inhernet in the basic EBNF grammars (i.e. without notes)
fn(){..} as a?
/*/, where the * can be a wildcard or a
multiplicationmap{a:*:c}
The grammars use an experimental 'set-subtraction' operator ¬ to
indicate certain reserved keywords such as limitations on function names:
FunctionCall: EQName ¬ reservedFunctionNames, ArgumentList.
reservedFunctionNames: types |
commands.
types: "attribute"; "comment"; ... .
commands: "fn"; "function"; "if"; "switch"; "typeswitch".
Removal of the operator and its RH argument will permit the grammar to run on a 1.0
conformant iXML processor, though now comment() can be ambiguous. The
operator is currently used on the productions for FunctionCall,
NamedFunctionRef, DirCommentContents,
CompPIConstructor, ElementContentChar,
QuotAttrContentChar and AposAttrContentChar and indirectly
from CompElemConstructor and CompAttrConstructor (I can
arrange for such grammars to be generated - let me know if you wish so.)
body++(s1,s2)
a/(b|c)/d failed whereas
a/(b |c)/d (trailing space) succeededjwL: namespace), corresponding to
the signature and semantics given in the current draft of XPath and XQuery
Functions and Operators 4.0
naming
production of Invisible XML
Specification - Working Draft where names can have optional
aliases to be used in XML tree production. (experimental) A ¬ B which matches
if A matches and B does not match at the same
end-character position. E.g. [L]+ ¬ "if" will not match
if, but will match i or iff.